User:StasFomin/DYI Java Profiling

У меня сегодня будет доклад про «Сделай себе сам профилирование на Яве». Слайды будут на английском, доклад я буду делать на русском. Слайдов очень-очень много, а времени не так много, поэтому я буду какие-то очень быстро проскакивать, и постараюсь оставить больше времени в конце на вопросы, и может быть даже где-то в середине. В принципе, не стесняйтесь, если захочется вдруг что-то спросить или уточнить, и даже меня прервать. Я лучше подробнее освещу то, что вам интересно, чем буду просто рассказывать то, что я хотел рассказать.
Доклад основан на реальном опыте, мы в компании больше десяти лет занимаемся созданием сложных, очень высоконагруженных финансовых приложений, работающих с большими массивами данных, с миллионами котировок в секунду, c десятками тысяч пользователей онлайн, и там, при такой работе, всегда речь идет о профилировании приложения.
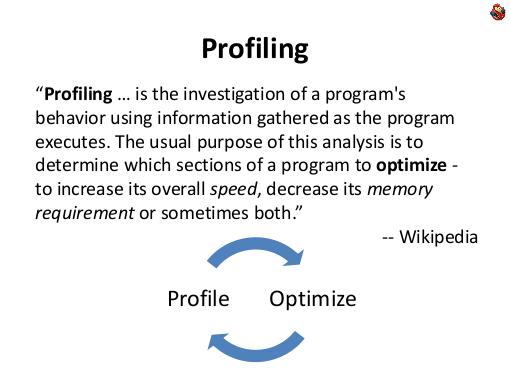
Профилирование приложения — неизбежный компонент любой оптимизации, оптимизация без профилирования невозможна. Вы профилируете, находите узкие места, оптимизируете-профилируете, это постоянный цикл.

Почему доклад называется «Do It Yourself Java Profiler», зачем что-то делать самому? Есть же огромное количество готовых инструментов, которые помогают профилировать — собственно профилировщики, и подобные инструменты.
Но дело в том, что во-первых, может быть проблема со сторонним инструментом. Вы просто по каким-то соображениям — надежности или безопасности, можете не иметь возможности запустить сторонний инструмент на каком-то живом окружении. А к сожалению, частенько приходится профилированием заниматься не только на тестовой платформе, но и на живой платформе, и не всегда для высоконагруженной платформе у вас есть возможность и ресурсы сделать идентичную копию системы и запустить под такой же нагрузкой. А многие узкие места могут выявится только под большой нагрузкой, только при очень специфичных условиях. Вы видите, что система работает не так, но вы не понимаете, почему. Какой именно шаблон нагрузки нужно для него создать, чтобы проблема проявилась — поэтому профилировать часто нужно именно живую систему.
Мы, когда пишем финансовые приложения, у нас есть еще задача обеспечить надежность системы. И мы делаем не «банки», где главное — не потерять ваши деньги, но которые могут быть часами недоступны. Мы делаем брокерские системы онлайн-торговли, где постоянно 24×7 доступность систем, это одна из ключевых их качеств, они никогда не должны падать.
И я уже говорил, что вся индустрия зарегулирована, и мы иногда не можем какой-то сторонний продукт использовать на реальной системе.
Но и инструменты частенько непрозрачны. Да, есть документация, которая описывает «что», но она не описывает, как именно он достает эти результаты, и не всегда можно понять, что он собственно намерял.
Причем даже если инструмент с открытым кодом, это ничего не меняет, потому что этого кода много, вы убъете кучу времени в нем разбираясь. Инструменты надо учиться, а делать что-то самому, конечно, намного приятней.

В чем проблема с изучением? Естественно, если вы используете какой-то инструмент часто, то стоит его учить. Если вы программируете каждый день в какой-то любимой вами среде разработки, вы ее знаете вдоль и поперек, и это знание, естественно, окупается вам сторицей.
А если вам нужно что-то сделать раз в месяц, например, раз в месяц вам нужно ради баги с производительностью заниматься профилированием, то не факт, что изучение соответствующего инструмента окупиться. Конечно же, если нет ситуации, когда инструмент решать задачу в разы быстрее.
Делая что-то своими руками, вы можете переиспользовать ваши знания. Например, у вас есть знания языков программирования, своих инструментов, вы можете их углубить, расширить, уточнить, глубже изучив те инструменты, которые у вас уже есть, вместо изучения нового.

Почему доклад о Java? Ну мало того, что наша компания программирует на Java, это ведущий язык 2001 года по индексу TIOBE, отлично подходит для enterprise приложений. А для данной конкретной лекции вообще замечательно — потому что Java — это managed язык, работает в виртуальной машине, и именно профилирование в Java делается вообще очень легко.

Я буду рассказывать во-первых, просто о том, как многие проблемы профилирования решить написав некий код на Java. Скажу о возможностях Java-машин, которые можно использовать, и расскажу о такой технике, как манипулирование байт-кодом.
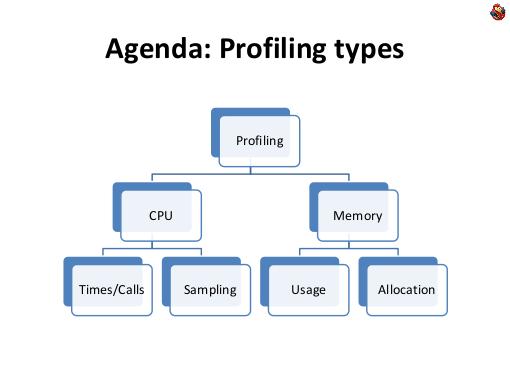
Мы посмотрим сегодня на профилирование как CPU, так и памяти. Я расскажду про разные техники.

Профилирование CPU. Самый простой способ, это просто взять и запрограммировать. Если вам нужно разобраться, куда, сколько, чего, в вашей программе занимает времени, и сколько раз вызывается, то самый-самый простой способ: не надо никаких инструментов, ничего — написать просто несколько строчек кода.
В Java есть замечательная функция «currentTimeMillis», которая возвращает текущее время. Можно ее замерять в одном месте, замерять в другом, а дальше можно посчитать, сколько раз это сделано, суммарное время, минимальное и максимальное время, все что угодно. Самый такой простой способ. DIY в своей максимальной простоте и примитивизме.
Как ни странно, на практике способ отлично работает, приносит кучу пользы — потому что быстр, удобен и эффективен.

Когда этот метод хорошо работает? Это замечательно работает для бизнес-методов — бизнес-метод большой, вызывается не очень часто, и вам нужно что-то про него измерить. Более того, написав этот код, раз уж вы его написали — он становится частью вашего приложения и частью функционала. Более менее любое современное большое приложение содержит интерфейсы управления, какие-то статистики, … и в общем производительность приложения — это одна из трех вещей, которую часто хочется видеть, чтобы приложение о себе выдавало, просто как часть своего функционала.
В этом смысле, запрограммировать приложение, чтобы оно само себя профилировало, является логичным шагом. Вы увеличиваете функционал приложения, профилирование приложения становится частью его функционала. Особенно, если таким образом вы расставляете определения в ваших бизнес-методах, которых конечный пользователь вызывает, то конечному пользователю эта информация тоже будет осмысленна. Сколько раз и какие методы вызывались, сколько по времени отрабатывали и так далее. Информация, которую вы собираете, в данном случае, при данном подходе, полностью под вашим контролем.
Можете замерять количество вызовов, минимальное время, максимальное время, среднее считать, можете строить гистограммы распределения времени выполнения, считать медианы и персентили. Можете разные пути исполнения в коде отслеживать по разному, как в этом примере, кто успел разглядеть, пока я говорил, обратил внимание, что в зависимости от пути исполнения, мы записываем разную статистику: как часто результат запроса попал в кеш, и сколько времени это заняло, и как часто запросу пришлось лезть в базу данных, и сколько времени это заняло.
Это возможно, если вы этот код пишете сами, собираете статистику, встраиваете сами в свое приложение.

Более того, вам, как человеку, который занимается циклом профилирования-оптимизации, вы потом эту информацию используете, что же в вашем приложении происходит, эта информация всегда находится внутри вашего приложения, код работает в живой системе. У вас произошел какой-то неудачный день, что-то система не так работала, вы можете посмотреть в логах эту статистику, разобраться, и так далее.
Замечательная методика, нет никаких сторонних инструментов, только немножко кода на яве.
Что же делать, если методы короче, и вызываются чаще?
Дело в том, что такой прямой метод уже не подойдет, потому что метод «currentTimeMillis» не быстрый, и меряет только в миллисекундах.
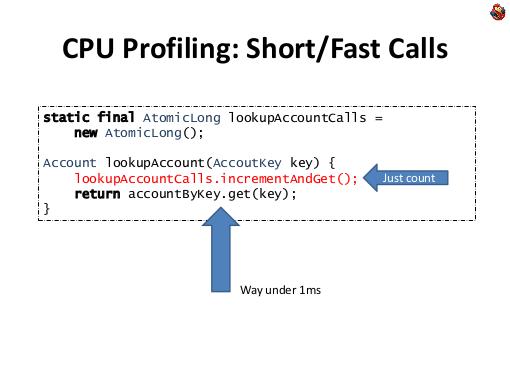
Если вам нужно замерить только количество вызовов, то достаточно быстро можно это сделать используя Java-класс «AtomicLong». С его помощью, вы можете внося минимальный вклад в производительность, посчитать количество вызовов какого-нибудь интересующего вас метода. Это будет работать до десятков тысяч вызов в секунду, не сильно искажая работу самого приложения.

Что же делать, если вам нужно еще замерить время выполнения? Замер времени исполнения коротких методов — это очень сложная тема. Стандартными никакими методами она не решается, несмотря на то, что в Java есть метод «systemNanoTime», он эти проблемы не решает, он сам по себе медленный, и с помощью него что-то быстрое сложно замерить.
Единственный реальный выход — это использовать нативный код, на x86 процессора есть такая замечательная инструкция, которая возращает счетчик количества тактов процессора. Напрямую к ней доступа нет, можно написать на C однострочный метод, который вызывает «rdtsc», а дальше слинковать его с Java-кодом, и вызывать из Java. Этот вызов вам займет сто тактов, и если вам нужно замерить кусок кода, который занимают тысячу-другую тактов, то это осмысленно, если у вас идет оптимизация каждого машинного такта, и вы хотите понять, «плюс-минус», «быстрее-медленнее», как вы работаете. Это действительно редкий случай, когда вам нужно оптимизировать каждый такт.
Чаще всего, когда речь идет о каких-то более коротких кусках кода, и более часто вызываемых, используют другой подход, который называется «семплирование». Вместо точных замеров, сколько раз и чего вызывается, вы периодически анализируете выполнение программы, смотрите, где она исполняется, в произвольные моменты времени, например — раз в секунду, или раз в десять секунд.

Смотрите, где происходит исполнение, и считаете, в каких местах вы застаете свою программу часто. Если у вас в программе есть строчка, в которой она тратит все, или по крайней мере 90% своего времени, например, какой-нибудь цикл, а там, в глубине, какая-то строчка, то скорее всего, при остановке исполнения вы ее в этой строчке и застанете.
Такое место в программе называется «горячей точкой». Это всегда замечательный кандидат для оптимизации. Что классно — есть встроенная фукнция под названием «thread dump», чтобы получить дамп всех потоков. В Windows она делается путем нажатия CTRL-Break на консоли, а на Linux и других юниксах это делается посылкой третьего сигнала, командой «kill -3».

В этом случае, Java-машина на консоль выводит подробное описание состояния всех потоков. И если у вас действительно есть горячее место в коде, то скорее всего программу там и застанете. Поэтому опять же, когда у вас проблема производительности с кодом, не надо бежать к профилировщику, не надо ничего делать. Видите, что тормозит, сделайте хоть один thread dump, и посмотрите. Если у вас одно горячее место, в котором программа тратит все время, вы в thread dump и увидите эту строчку, в своей любимой среде разработки, без использования каких-нибудь сторонних, дополнительных инструментов. Посмотрите этот код, изучите, оптимизируйте — либо он слишком часто вызывается, либо он медленно работает, дальше уже разбор полетов, оптимизация, либо дальнейшее профилирование.
Также в современных Java-машинах есть замечательная утилита «jstack», ей можно передать идентификатор процесса, и получить на выходе thread dump.
Сделайте не один thread dump, сделайте несколько thread dumpов. Если первый ничего не выловит, посмотрите еще на пару-тройку. Может у вас в горячей точке не сто процентов времени программа проводит, а 50%. Сделав нескольок thread dumpов, вы явно в хоть какой-то из этих моментов, достанете ваш код из горячей точки, и глазками посмотрите те места, где вы застали ваш код.

Эту идею можно развить дальше. Можно запустив ява-машину, перенаправить ее выход в файл, и запустить скрипт, который делает thread dump каждые три секунды. Это можно делать совершенно спокойно на живой системе, без какого либо риска что-то с ней сделать. Потому что сам сбор thread dump досточно быстрая процедура, занимает от силы 100 миллисекунд, даже при очень большом количестве тредов.
А если вы пишите на яве, то скорее всего ваша система не hard real time
13:58